下面的流程图展示了pi agent从用户输入自然语言任务到返回结果的完整工作流程。
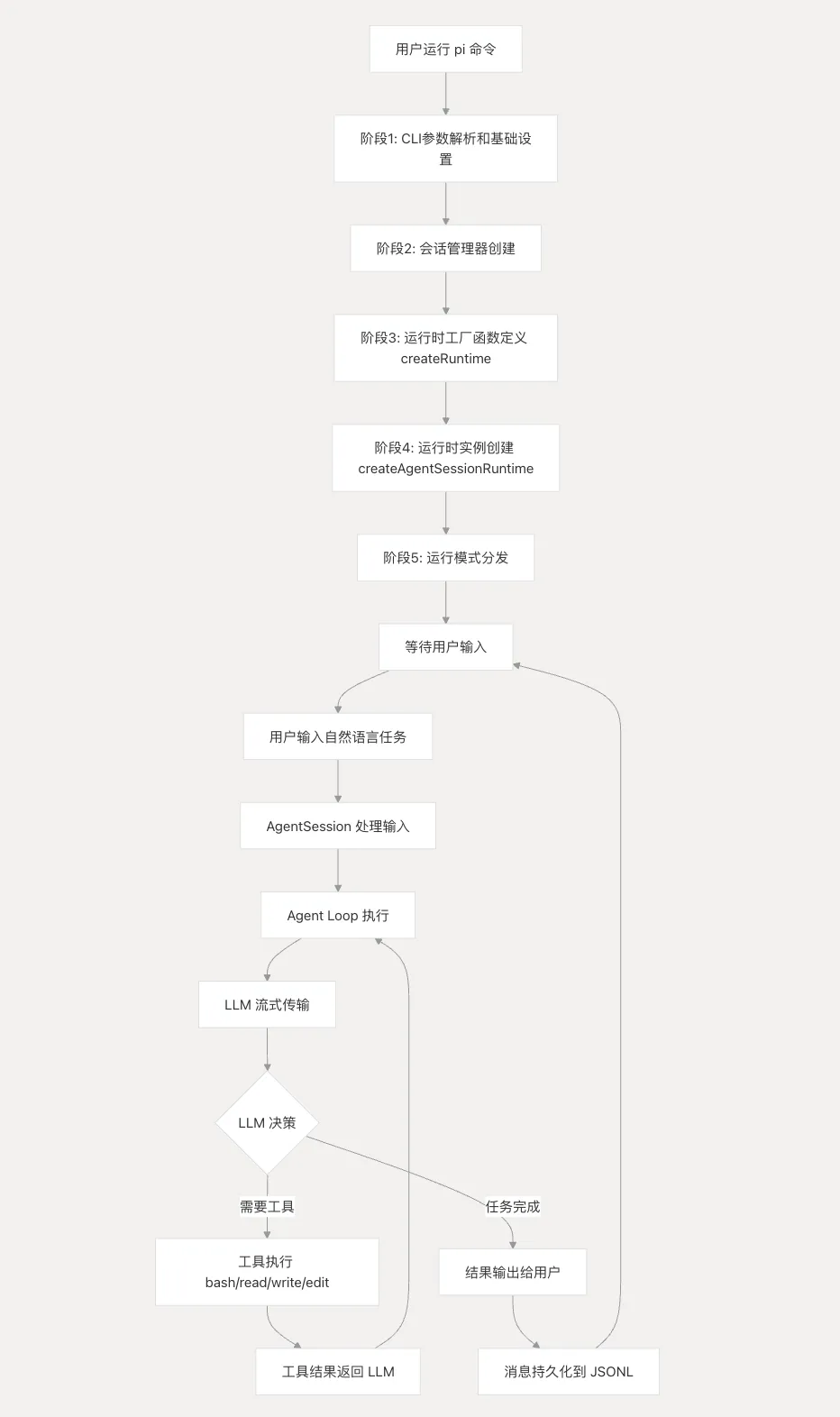
包含以下几个关键步骤:
初始化阶段 – 建立安全可信的运行环境
用户提示处理 – 标准化多样化的输入格式
Agent Loop 执行 – LLM 与工具的动态交互
会话持久化 – 确保数据完整性和可回溯性
下面将深入分析每个阶段的技术实现细节和部分源码分析。
1.初始化
pi agent的初始化分为以下5个步骤:CLI 参数解析和基础设置、会话管理器创建、运行时工厂函数定义、运行时实例创建和运行模式分发。
1.1 CLI 参数解析和基础设置
当运行pi命令启动cli时,初始化流程从 main 函数入口开始,作为一个统一的入口来处理各种运行模式(交互式、单次输出、RPC)、管理会话状态,加载配置,并将这些组件组装成可运行的系统。
系统首先处理基础环境设置,包括检测离线模式和 Windows 平台的特殊清理。然后检查是否执行特殊命令,如包管理命令 或配置命令,这些命令会立即执行并退出程序。
接着系统解析 CLI 参数,将用户输入转换为结构化的配置对象。基于解析结果,系统处理版本查询和会话导出等一次性操作。然后根据终端状态确定运行模式(interactive、rpc 或 print),这对后续的用户交互方式至关重要。
function resolveAppMode(parsed: Args, stdinIsTTY: boolean, stdoutIsTTY: boolean): AppMode {
if (parsed.mode === "rpc") {
return "rpc";
}
if (parsed.mode === "json") {
return "json";
}
if (parsed.print || !stdinIsTTY || !stdoutIsTTY) {
return "print";
}
return "interactive";
}系统验证参数的合法性 ,运行必要的迁移以更新旧版本数据 ,最后创建启动设置管理器,这个管理器用于后续的会话查找。整个流程确保了在进入实际业务逻辑之前,所有基础配置都已正确设置,避免了运行时的配置错误。
const startupSettingsManager = SettingsManager.create(cwd, agentDir);
reportDiagnostics(collectSettingsDiagnostics(startupSettingsManager, "startup session lookup"));1.2 创建会话管理器
用户启动 pi agent 时有多种需求场景:创建新会话、继续之前的对话、从现有会话分支、或者只是查看帮助信息而不需要持久化会话。这些不同的需求通过不同的 CLI 参数(如 --session、--continue、--fork、--no-session 等)来表达。
这部分的关键代码在packages/coding-agent/src/main.ts的 createSessionManager方法:
let sessionManager = await createSessionManager(parsed, cwd, sessionDir, startupSettingsManager);具体的参数处理包括以下参数:
判断顺序遵循参数优先级:首先检查特殊参数(如 --fork),如果存在则解析源会话路径并调用 forkSessionOrExit() 创建分支。接着是 --session 参数,解析路径后调用 SessionManager.open() 打开指定会话,如果会话来自不同项目则提示用户 fork。--resume 参数会启动交互式选择器让用户从会话列表中选择。
其他参数也有专门处理:--continue 直接调用 SessionManager.continueRecent() 恢复最近使用的会话,--session-id 会检查该 ID 是否已存在,存在则打开否则创建新会话。如果没有任何参数匹配,默认调用 SessionManager.create() 创建全新会话。这种设计确保了所有会话管理场景都有明确的处理路径,参数冲突通过 validateForkFlags() 和 validateSessionIdFlags() 在调用前进行校验,避免了运行时错误。
例如下方代码就是检查fork参数逻辑:
if (parsed.fork) {
if (parsed.sessionId) {
const existingTarget = await findLocalSessionByExactId(parsed.sessionId, cwd, sessionDir);
if (existingTarget) {
console.error(chalk.red(`Session already exists with id '${parsed.sessionId}'`));
process.exit(1);
}
}
const resolved = await resolveSessionPath(parsed.fork, cwd, sessionDir);
switch (resolved.type) {
case "path":
case "local":
case "global":
return forkSessionOrExit(resolved.path, cwd, sessionDir, parsed.sessionId);
case "not_found":
console.error(chalk.red(`No session found matching '${resolved.arg}'`));
process.exit(1);
}
}createSessionManager方法通过一系列条件判断决定使用哪种会话创建策略。是创建新会话还是加载会话,这涉及到解析会话路径、创建新会话或恢复已有会话。
1.3 createRuntime工厂函数定义
Pi agent 需要在多种场景下创建运行时环境:首次启动、用户执行 /new、/resume、/fork 命令,或导入会话时。每种场景都需要相同的初始化逻辑:项目信任验证、模型选择、工具配置、服务创建等。如果没有统一的工厂函数,这些逻辑会在每个场景中重复实现,导致代码冗余和一致性风险。createRuntime 工厂函数解决了这个问题,它将所有初始化逻辑封装在一个可复用的函数中,确保无论从哪个入口创建运行时,都遵循相同的初始化流程。
工厂函数接收核心参数:工作目录 cwd、代理目录 agentDir、会话管理器 sessionManager、会话开始事件 sessionStartEvent 和项目信任上下文 projectTrustContext 。
初始化流程首先处理项目信任决策。系统检查项目是否需要信任资源,如果不需要则自动信任 。对于需要信任的项目,系统根据缓存、CLI 参数和信任存储决定信任状态,避免重复询问用户。信任决策结果会被缓存到 Map 中,供后续使用。
会话工作目录验证
系统首先通过 getMissingSessionCwdIssue() 检查会话文件中存储的 cwd 是否实际存在。如果目录不存在,根据运行模式采取不同策略:在交互模式下,通过 promptForMissingSessionCwd() 询问用户是否在当前目录继续,如果用户同意则使用当前目录重新打开会话;在非交互模式下(如 RPC 或 print),直接报错退出。此外,如果用户通过 --name 参数指定了会话名称,系统会将其附加到会话信息中。最后,系统初始化项目信任存储,为后续的项目资源访问权限决策做准备。
项目信任决策
项目信任决策从 autoTrustOnReloadCwd 判断开始,如果项目不需要信任资源(没有 .pi 目录等),系统会自动信任该目录。对于需要信任的项目,系统通过多层决策来确定信任状态:首先检查缓存中是否已有决策,然后检查 CLI 是否提供了覆盖参数,最后从持久化的 trustStore 中读取历史决策。
当需要解析项目信任时,系统会为资源加载器提供一个 resolveProjectTrust 回调。这个回调在加载扩展时被调用,允许扩展通过事件系统影响信任决策。实际的 resolveProjectTrusted 函数会尝试通过扩展事件获取决策,如果扩展没有响应,则查看 trustStore 中的历史记录。如果没有历史记录且默认策略是 "ask",系统会启动交互式 UI 让用户选择。
最终决策会被缓存到 projectTrustByCwd Map 中,避免在同一运行时内重复计算。这个缓存确保了当会话切换目录或重新加载资源时,信任决策的一致性和性能。
路径决策和资源配置
路径解析流程首先调用 resolveCliPaths() 函数处理用户提供的路径。该函数检查路径是否为本地路径(相对路径),如果是则使用当前工作目录将其转换为绝对路径。系统依次解析扩展路径、技能路径、提示模板路径和主题路径。
解析完成后,这些路径被配置到 resourceLoaderOptions 对象中。这个对象作为配置参数传递给资源加载器,包含:
additionalExtensionPaths、additionalSkillPaths等字段:指定额外的资源加载路径noExtensions、noSkills等布尔字段:控制是否禁用特定类型的资源
这种设计使得资源加载器可以根据统一的配置决定从哪里加载资源以及加载哪些资源,同时支持用户通过 CLI 参数灵活控制资源加载行为。
模型作用域解析和会话选项构建
模型解析流程从获取模型模式开始。系统首先检查 CLI 参数 --models,如果没有提供则从设置管理器读取已启用的模型列表。然后调用 resolveModelScope() 将这些模式解析为具体的模型列表。这个过程支持 glob 模式匹配(如 *sonnet* 可以匹配所有包含 "sonnet" 的模型),也支持精确匹配和前缀匹配。每个模型都可以配置思考级别(如 :high 后缀)。
解析完成后,系统调用 buildSessionOptions() 构建完整的会话配置。这个函数处理多个优先级:CLI 指定的模型优先级最高,其次是作用域模型中的第一个或默认保存的模型。思考级别也遵循类似的优先级规则(CLI > 模型配置)。工具配置包括禁用所有工具、禁用内置工具、指定特定工具或排除特定工具。
最后,如果用户通过 CLI 提供了 API 密钥,系统会将其设置到认证存储中,确保该密钥仅用于当前运行时,不会永久保存。这种设计既支持临时覆盖,又保持了安全性。
创建AgentSession实例
创建运行时设置管理器,传入信任状态确保设置加载遵循信任策略。接着调用 createAgentSessionServices 创建核心服务,包括认证存储、模型注册表和资源加载器。资源加载器配置包括扩展路径、技能路径、信任解析回调等,确保资源在正确的安全上下文中加载。
系统收集诊断信息,包括项目信任诊断、服务加载错误和设置问题。这些诊断会在运行时启动时显示,帮助用户发现配置问题。
模型解析阶段从 CLI 参数或设置中获取模型模式,通过 resolveModelScope 解析为具体的模型列表。buildSessionOptions 函数根据解析结果和 CLI 参数构建会话选项,包括模型选择、思考级别和工具配置。如果用户提供了 API 密钥,系统会设置到认证存储中供运行时使用。
最后,createAgentSessionFromServices 使用服务和配置创建 AgentSession 实例。工厂函数返回会话、服务和诊断信息的完整对象,供上层运行时包装器使用。整个流程确保运行时在正确的配置和安全环境中启动。
最后就是创建运行时进程。
const runtime = await createAgentSessionRuntime(createRuntime, {
cwd: sessionManager.getCwd(),
agentDir,
sessionManager,
});运行模式分发
创建后的AgentSessionRuntime,也就是上面代码中的runtime,最后根据运行模式分发到不同的处理函数:runRpcMode() 用于嵌入其他应用的 RPC 模式,runPrintMode() 用于单次输出模式,new InteractiveMode() 用于交互式 TUI 模式。
运行模式分发逻辑位于 main 函数的最后阶段。系统首先通过 resolveAppMode 根据终端状态(process.stdin.isTTY、process.stdout.isTTY)和 CLI 参数确定运行模式。然后根据 appMode 进行分支处理:
- RPC 模式:当
appMode === "rpc"时,系统启动 JSON-RPC 服务器,通过runRpcMode(runtime)进入远程调用处理循环,等待外部程序的 JSON-RPC 请求。 - Interactive 模式:当
appMode === "interactive"时,系统创建InteractiveMode实例,传入运行时、迁移的提供商、模型回退消息、初始消息等配置。然后调用interactiveMode.run()启动交互式 TUI 主循环,等待用户在终端中输入命令。 - Print 模式:作为默认分支(else),系统调用
runPrintMode(runtime, {...}),处理单次输入后输出结果并立即退出。这种模式适用于脚本调用或管道场景。
下面是模式分发的代码:
if (appMode === "rpc") {
printTimings();
await runRpcMode(runtime);
} else if (appMode === "interactive") {
const interactiveMode = new InteractiveMode(runtime, {
migratedProviders,
modelFallbackMessage,
autoTrustOnReloadCwd,
initialMessage,
initialImages,
initialMessages: parsed.messages,
verbose: parsed.verbose,
});
if (startupBenchmark) {
await interactiveMode.init();
time("interactiveMode.init");
printTimings();
interactiveMode.stop();
stopThemeWatcher();
if (process.stdout.writableLength > 0) {
await new Promise<void>((resolve) => process.stdout.once("drain", resolve));
}
if (process.stderr.writableLength > 0) {
await new Promise<void>((resolve) => process.stderr.once("drain", resolve));
}
return;
}
printTimings();
await interactiveMode.run();
} else {
printTimings();
const exitCode = await runPrintMode(runtime, {
mode: toPrintOutputMode(appMode),
messages: parsed.messages,
initialMessage,
initialImages,
});
stopThemeWatcher();
restoreStdout();
if (exitCode !== 0) {
process.exitCode = exitCode;
}
return;
}2.用户提示处理
Pi agent 需要一个统一的入口来处理用户输入的自然语言任务。无论用户是在交互式 TUI 中输入、通过管道传递文本,还是通过 RPC 发送命令,系统都需要将这些输入转换为 Agent 可以理解和执行的消息格式。这个流程的核心问题是:如何将原始用户输入(可能包含文件引用、图片、特殊命令)转换为标准化的 AgentMessage,并触发 Agent Loop 开始处理。
用户提示处理流程从交互模式的主循环开始。当用户在编辑器中输入内容并提交时,getUserInput() 从编辑器获取文本,然后调用 session.prompt(userInput) 将输入发送到 AgentSession。
// Main interactive loop
while (true) {
const userInput = await this.getUserInput();
try {
await this.session.prompt(userInput);
} catch (error: unknown) {
const errorMessage = error instanceof Error ? error.message : "Unknown error occurred";
this.showError(errorMessage);
}
}AgentSession 层负责预处理和扩展拦截。它首先检查输入是否以 / 开头,如果是则尝试执行扩展命令(如 /model、/compact)。如果不是命令,它会展开文件引用的提示模板,然后调用底层的 agent.prompt()。
if (expandPromptTemplates && text.startsWith("/")) {
const handled = await this._tryExecuteExtensionCommand(text);
if (handled) {
// Extension command executed, no prompt to send
preflightResult?.(true);
return;
}
}Agent 层将输入标准化为 AgentMessage 格式,支持纯文本、消息数组和图片附件。标准化后,通过 runPromptMessages() 启动 Agent Loop,这会触发 LLM 调用和工具执行的完整循环。
private async _runAgentPrompt(messages: AgentMessage | AgentMessage[]): Promise<void> {
try {
await this.agent.prompt(messages);
while (await this._handlePostAgentRun()) {
await this.agent.continue();
}
} finally {
this._flushPendingBashMessages();
}
} private async runPromptMessages(
messages: AgentMessage[],
options: { skipInitialSteeringPoll?: boolean } = {},
): Promise<void> {
await this.runWithLifecycle(async (signal) => {
await runAgentLoop(
messages,
this.createContextSnapshot(),
this.createLoopConfig(options),
(event) => this.processEvents(event),
signal,
this.streamFn,
);
});
}整个流程设计为分层架构:交互模式负责 UI 交互,Session 层负责会话管理和扩展集成,Agent 层负责核心的 LLM 循环逻辑。这种分离使得同一套 Agent 核心逻辑可以在不同的运行模式(交互式、打印、RPC)中复用。
3.Agent Loop执行
LLM 模型只能生成文本,无法直接执行操作(如读取文件、运行命令)。Agent Loop 解决的核心问题是:如何让 LLM 能够循环地与外部世界交互,直到完成任务。它实现了经典的 "agent loop" 模式:发送上下文 → 获取响应 → 如果需要则执行工具 → 将工具结果反馈给 LLM → 重复直到 LLM 完成任务。
Agent Loop 的执行从 runAgentLoop() 函数开始,它初始化消息上下文并启动主循环 runLoop()。主循环是一个 while (true) 循环,持续处理 LLM 响应和工具调用。
3.1 LLM流式传输
当用户向 AI agent 输入任务时,需要与 LLM 提供商(如 Anthropic、OpenAI)进行通信。这些提供商支持流式传输,可以在生成响应时实时返回 token,而不是等待完整响应。这提供了更好的用户体验,因为用户可以立即看到结果,同时 agent 也可以在响应生成时开始处理工具调用。
每次循环首先调用 streamAssistantResponse() ,它将 AgentMessage 转换为 LLM 兼容格式,通过 streamSimple() 向 LLM 提供商发起请求,并流式处理响应事件(文本增量、工具调用增量等)。
流式传输过程从消息格式转换开始。agent 使用 AgentMessage 格式,但 LLM 提供商期望标准的 Message 格式。为了解决这个问题,pi agent中有一个重要的函数,convertToLlm 函数执行此转换,过滤掉不需要的消息类型(如自定义消息)。
然后构建 LLM 上下文对象,包含系统提示、消息和可用工具定义。API 密钥通过 getApiKey 回调动态解析,这对于处理过期令牌很重要。
实际的 LLM 调用通过 streamSimple 函数发起,它是 pi-ai 包提供的标准流式接口。此函数处理认证、超时、重试和提供商标头。
// Convert to LLM-compatible messages (AgentMessage[] → Message[])
const llmMessages = await config.convertToLlm(messages);
// Build LLM context
const llmContext: Context = {
systemPrompt: context.systemPrompt,
messages: llmMessages,
tools: context.tools,
};
const streamFunction = streamFn || streamSimple;
// Resolve API key (important for expiring tokens)
const resolvedApiKey =
(config.getApiKey ? await config.getApiKey(config.model.provider) : undefined) || config.apiKey;
const response = await streamFunction(config.model, llmContext, {
...config,
apiKey: resolvedApiKey,
signal,
});流式响应作为事件流返回。主循环迭代这些事件,根据事件类型采取不同行动:
- start 事件:创建部分消息并发出 message_start 事件
- text_delta/thinking_delta/toolcall_delta 事件:更新部分消息并发出 message_update 事件
- done/error 事件:获取最终消息,发出 message_end 事件,并返回结果
下面是事件流处理源码:
for await (const event of response) {
switch (event.type) {
case "start":
partialMessage = event.partial;
context.messages.push(partialMessage);
addedPartial = true;
await emit({ type: "message_start", message: { ...partialMessage } });
break;
case "text_start":
case "text_delta":
case "text_end":
case "thinking_start":
case "thinking_delta":
case "thinking_end":
case "toolcall_start":
case "toolcall_delta":
case "toolcall_end":
if (partialMessage) {
partialMessage = event.partial;
context.messages[context.messages.length - 1] = partialMessage;
await emit({
type: "message_update",
assistantMessageEvent: event,
message: { ...partialMessage },
});
}
break;
case "done":
case "error": {
const finalMessage = await response.result();
if (addedPartial) {
context.messages[context.messages.length - 1] = finalMessage;
} else {
context.messages.push(finalMessage);
}
if (!addedPartial) {
await emit({ type: "message_start", message: { ...finalMessage } });
}
await emit({ type: "message_end", message: finalMessage });
return finalMessage;
}
}
}这种设计允许 agent 在 LLM 生成响应时实时更新 UI,并在检测到工具调用时立即开始执行,而不必等待完整响应完成。
3.2 工具执行
如果 LLM 响应包含工具调用,循环会调用 executeToolCalls() 。这个过程包括:准备工具调用(验证参数、调用 beforeToolCall 钩子)、执行工具(调用 tool.execute(),支持部分结果流式传输)、调用 afterToolCall 钩子(允许扩展修改结果),最后将工具结果转换为 tool_result 消息。
工具结果会添加到上下文中,循环继续,直到 LLM 不再请求工具调用且没有后续消息,此时循环结束并返回所有新消息。
4.会话持久化
系统必须在每个消息完成后立即保存,而不是等到会话结束,以防止崩溃或中断导致数据丢失。
AgentSession 通过订阅 Agent 的事件流来实现持久化。当 Agent 执行时,它会发出各种事件(message_start, message_end, tool_execution 等)。AgentSession 的 _handleAgentEvent 是主处理器,拦截所有这些事件。
处理流程分为三步:
- 扩展系统优先:首先通过
_emitExtensionEvent通知扩展系统,允许扩展在消息持久化前进行修改或拦截。 - 通知订阅者:通过
_emit通知所有 UI 层订阅者(如交互模式、RPC 模式),确保界面实时更新。 - 持久化消息:在
message_end事件中,调用sessionManager.appendMessage将消息写入 JSONL 文件。这个文件是会话的唯一真实来源,支持历史回溯和分支操作。
所有消息类型(user、assistant、toolResult、custom)都会被持久化,但特殊类型(如 bashExecution、compactionSummary)有专门的持久化逻辑。
// Regular LLM message - persist as SessionMessageEntry
this.sessionManager.appendMessage(event.message);5.总结
Pi Agent 工作流程展示了一个优秀软件系统的模块化设计思想。初始化模块负责环境搭建和安全控制,构成了系统的基础设施层;用户提示处理模块作为输入网关,实现了多样化输入的统一转化;Agent Loop 模块作为核心引擎,通过流式通信和工具扩展机制赋予了 LLM 与现实交互的能力;持久化模块则建立了完整的数据追溯链条。这四个模块层层递进又相对独立,形成了清晰的职责边界和松耦合的架构关系。这不仅保证了系统的可维护性和扩展性,更为后续的功能迭代和技术演进奠定了坚实基础。







