[toc]
此文章用来记录Redis学习笔记,学习路径是极客时间上蒋德钧老师的《Redis核心技术与实战》
解构键值型数据库
我们知道Redis是一个典型的键值型数据库,那一个普通的键值型数据库整体上应该有哪几个模块组成呢?
一个键值型数据库主要包括以下几个模块:访问框架、操作模块、索引模块、存储模块
如下图所示:

Redis的数据结构
Redis支持的数据结构,也即数据存储类型是我们熟知的五大种:字符串(string)、列表(list)、哈希(hash)、集合(set)、有序集合(sorted set)
其实,我们常说的这五种数据结构只是Redis在键值对中存储的数据形式,可以理解为是经过Redis底层操作或者修改之后展示给客户端看到的数据结构。那Redis底层真正的数据结构是什么呢?
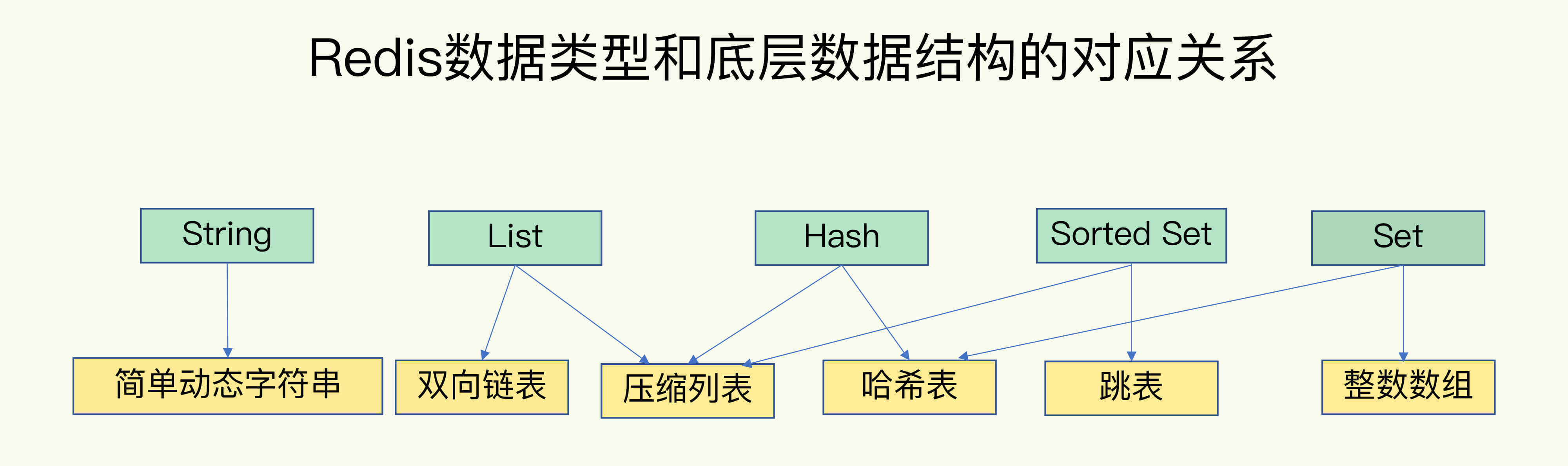
简单来说,Redis底层的数据结构是6种,分别是简单动态字符串、双向链表、压缩列表、哈希表、跳表和整数数组。他们和数据类型的对应关系如下图所示:
Redis用一个全局哈希表来存储键值对,每一个键值对作为一个哈希桶被保存在全局哈希表中,即可以通过O(1)的时间复杂度找到这个哈希桶,即找到键值对的数据。但是哈希桶中存的并不是真正的键值对数据,而是指向他们的指针。所以,哈希桶中存的数据就不受数据类型的限制,所有的数据类型都存在哈希桶中,并通过指针找到真正的数据。
那底层的这几种数据类型是怎么组织数据呢?
我们先介绍一下压缩列表和跳表这两种数据结构。
- 压缩列表
压缩列表其实类似数组,但是他和普通数组不一样的地方在于,压缩列表在表头有三个字段 zlbytes、zltail和zllen,分别表示列表长度、列表尾的偏移量和列表中entry的个数,在表尾还有一个zlend,表示列表结束。
这样的数据结构,保证了再查找压缩列表查找第一个和最后一个元素的时候是O(1)的时间复杂度,但是查找其他的元素的时候仍然是O(n)的复杂度。
-
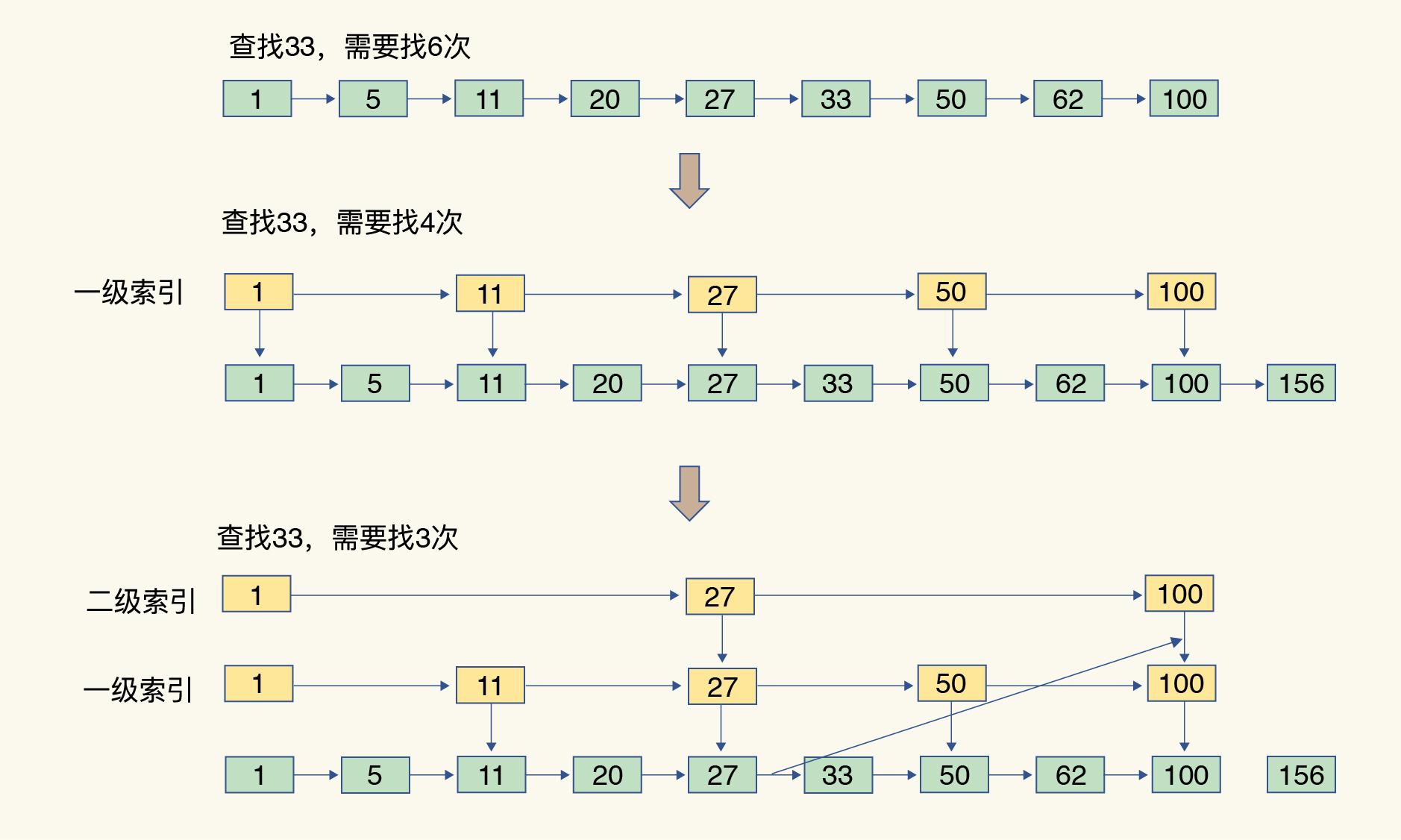
跳表
跳表是基于有序链表的改进,是通过增加多级索引来实现快速查找数据,整个过程是跳着找数据,所以被称为跳表。如下图所示:
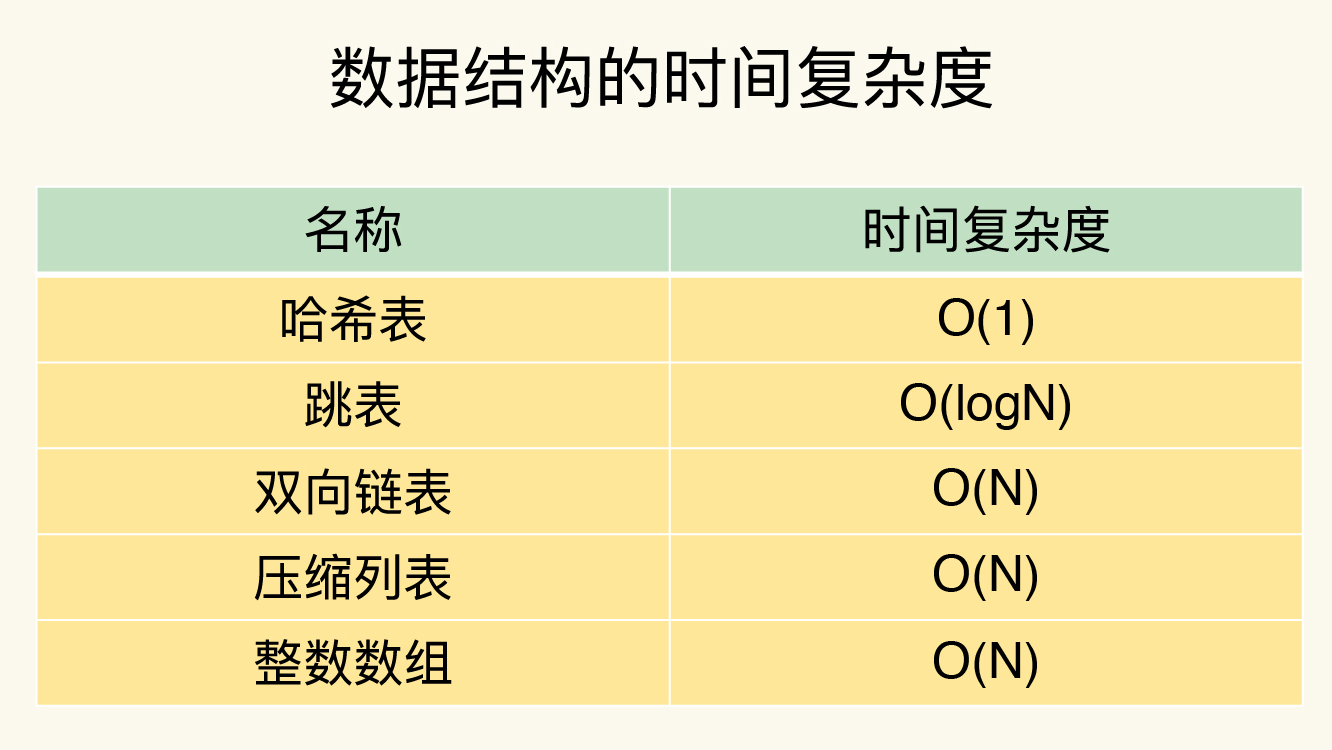
现在我们来整理下这几个数据结构的时间复杂度:
Redis 数据类型丰富,每个类型的操作繁多,我们通常无法一下子记住所有操作的复杂度。所以,最好的办法就是掌握原理,以不变应万变。

