在本文中,您将学习如何使Hugging Face Transformers微调 google/flan-t5-xl 的聊天和对话摘要。如果您已经了解 T5,那么 FLAN-T5 在所有方面都更胜一筹。在参数数量相同的情况下,这些模型已在 1000 多个额外任务中进行了微调,涵盖更多语言。
在本示例中,我们将使用 samsum 数据集,该数据集收集了约 1.6 万条带有摘要的类似信使的对话。对话由精通英语的语言学家创建并写下。
你将学习到以下内容:
- 设置开发环境
- 加载并预处理samsum数据集
- 微调并且评估 FLAN-T5
- 运行推理并总结 ChatGPT 对话
在开始之前,你需要有一个Hugging Face Account 来保存实验数据。
快速介绍: FLAN-T5,更好的 T5
与 Scaling Instruction-Finetuned Language Models 论文一起发布的 FLAN-T5 是 T5 的增强版,已在多种任务中进行了微调。论文探讨了指令微调,重点关注:(1) 扩展任务数量;(2) 扩展模型大小;(3) 在思维链数据上进行微调。论文发现,整体指令微调是提高预训练语言模型性能和可用性的通用方法。
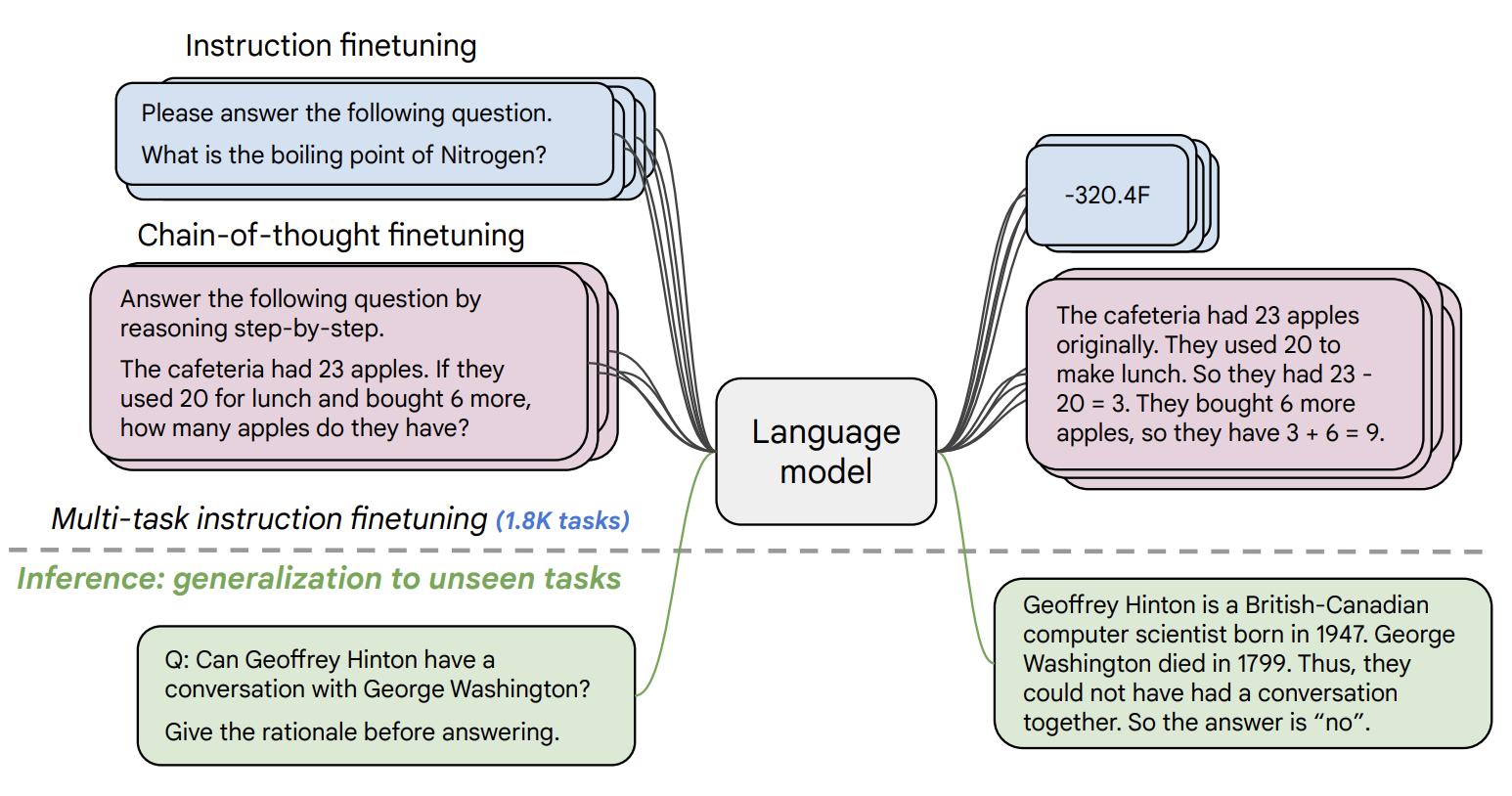
- Paper: https://arxiv.org/abs/2210.11416
- Official repo: https://github.com/google-research/t5x
现在我们已经了解了FLAN-T5,让我们开始吧?
注:本教程在包含英伟达 T4 的 g4dn.xlarge AWS EC2 实例上创建并运行。
1.设置开发环境
我们第一步是安装 Hugging Face 类库,包括 transformers 和 dataset。运行下面的命令,将会安装所需要的包。
# python
!pip install pytesseract transformers datasets rouge-score nltk tensorboard py7zr --upgrade
# install git-fls for pushing model and logs to the hugging face hub
!sudo apt-get install git-lfs --yes 本例将使用 Hugging Face Hub 作为远程模型版本服务。要将我们的模型推送到 Hub,您需要在 Hugging Face 上注册。如果你已经有一个账户,可以跳过这一步。有了账户后,我们将使用 huggingface_hub 软件包中的 notebook_login util 登录账户,并在磁盘上存储我们的令牌(访问密钥)。
from huggingface_hub import notebook_login
notebook_login()2.加载并预处理samsum数据集
我们将使用 samsum 数据集,该数据集收集了约 16K 条带有摘要的类似信使的对话。对话由精通英语的语言学家创建并记录下来。
{
"id": "13818513",
"summary": "Amanda baked cookies and will bring Jerry some tomorrow.",
"dialogue": "Amanda: I baked cookies. Do you want some?\r\nJerry: Sure!\r\nAmanda: I'll bring you tomorrow :-)"
}我们使用load_dataset()方法来加载samsum数据集。
from datasets import load_dataset
# Load dataset from the hub
dataset_id = "samsum"
dataset = load_dataset(dataset_id)
print(f"Train dataset size: {len(dataset['train'])}")
print(f"Test dataset size: {len(dataset['test'])}")
# Train dataset size: 14732
# Test dataset size: 819我们来检查下数据集。
from random import randrange
sample = dataset['train'][randrange(len(dataset["train"]))]
print(f"dialogue: \n{sample['dialogue']}\n---------------")
print(f"summary: \n{sample['summary']}\n---------------") 为了训练我们的模型,我们需要将输入(文本)转换为标记 ID。这项工作由 ? Transformers Tokenizer 完成。如果您不确定这意味着什么,请参阅《Hugging Face 课程》 chapter 6 。
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
model_id="google/flan-t5-base"
# Load tokenizer of FLAN-t5-base
tokenizer = AutoTokenizer.from_pretrained(model_id) 在开始训练之前,我们需要对数据进行预处理。抽象摘要是一项文本到文本的生成任务。这意味着我们的模型将以文本作为输入,并生成摘要作为输出。为此,我们需要了解输入和输出的长度,以便高效地批处理数据。
from datasets import concatenate_datasets
# The maximum total input sequence length after tokenization.
# Sequences longer than this will be truncated, sequences shorter will be padded.
tokenized_inputs = concatenate_datasets([dataset["train"], dataset["test"]]).map(lambda x: tokenizer(x["dialogue"], truncation=True), batched=True, remove_columns=["dialogue", "summary"])
max_source_length = max([len(x) for x in tokenized_inputs["input_ids"]])
print(f"Max source length: {max_source_length}")
# The maximum total sequence length for target text after tokenization.
# Sequences longer than this will be truncated, sequences shorter will be padded."
tokenized_targets = concatenate_datasets([dataset["train"], dataset["test"]]).map(lambda x: tokenizer(x["summary"], truncation=True), batched=True, remove_columns=["dialogue", "summary"])
max_target_length = max([len(x) for x in tokenized_targets["input_ids"]])
print(f"Max target length: {max_target_length}")def preprocess_function(sample,padding="max_length"):
# add prefix to the input for t5
inputs = ["summarize: " + item for item in sample["dialogue"]]
# tokenize inputs
model_inputs = tokenizer(inputs, max_length=max_source_length, padding=padding, truncation=True)
# Tokenize targets with the text_target keyword argument
labels = tokenizer(text_target=sample["summary"], max_length=max_target_length, padding=padding, truncation=True)
# If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
# padding in the loss.
if padding == "max_length":
labels["input_ids"] = [
[(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
]
model_inputs["labels"] = labels["input_ids"]
return model_inputs
tokenized_dataset = dataset.map(preprocess_function, batched=True, remove_columns=["dialogue", "summary", "id"])
print(f"Keys of tokenized dataset: {list(tokenized_dataset['train'].features)}")3.微调和评估 FLAN-T5
处理完数据集后,我们就可以开始训练模型了。因此,我们首先需要从 "Hugging Face Hub "加载我们的 FLAN-T5。在示例中,我们使用的是配备英伟达 V100 的实例,这意味着我们将对模型的基础版本进行微调。
from transformers import AutoModelForSeq2SeqLM
# huggingface hub model id
model_id="google/flan-t5-base"
# load model from the hub
model = AutoModelForSeq2SeqLM.from_pretrained(model_id) 我们希望在训练过程中对模型进行评估。训练器通过提供计算指标(compute_metrics)来支持训练过程中的评估。
评估摘要任务最常用的指标是 rogue_score(Recall-Oriented Understudy for Gisting Evaluation 的缩写)。该指标与标准准确率不同:它将生成的摘要与一组参考摘要进行比较。
我们将使用 evaluate 库来评估 rogue score。
import evaluate
import nltk
import numpy as np
from nltk.tokenize import sent_tokenize
nltk.download("punkt")
# Metric
metric = evaluate.load("rouge")
# helper function to postprocess text
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [label.strip() for label in labels]
# rougeLSum expects newline after each sentence
preds = ["\n".join(sent_tokenize(pred)) for pred in preds]
labels = ["\n".join(sent_tokenize(label)) for label in labels]
return preds, labels
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
result = {k: round(v * 100, 4) for k, v in result.items()}
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
result["gen_len"] = np.mean(prediction_lens)
return result 在开始训练之前,我们先要创建一个数据整理器(DataCollator),用于填充输入和标签。我们将使用 ? Transformers 库中的 DataCollatorForSeq2Seq。
from transformers import DataCollatorForSeq2Seq
# we want to ignore tokenizer pad token in the loss
label_pad_token_id = -100
# Data collator
data_collator = DataCollatorForSeq2Seq(
tokenizer,
model=model,
label_pad_token_id=label_pad_token_id,
pad_to_multiple_of=8
) 最后一步是定义我们希望用于训练的超参数(TrainingArguments)。我们正在利用训练器的 Hugging Face Hub 集成,将训练过程中的检查点、日志和指标自动推送到存储库中。
from huggingface_hub import HfFolder
from transformers import Seq2SeqTrainer, Seq2SeqTrainingArguments
# Hugging Face repository id
repository_id = f"{model_id.split('/')[1]}-{dataset_id}"
# Define training args
training_args = Seq2SeqTrainingArguments(
output_dir=repository_id,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
predict_with_generate=True,
fp16=False, # Overflows with fp16
learning_rate=5e-5,
num_train_epochs=5,
# logging & evaluation strategies
logging_dir=f"{repository_id}/logs",
logging_strategy="steps",
logging_steps=500,
evaluation_strategy="epoch",
save_strategy="epoch",
save_total_limit=2,
load_best_model_at_end=True,
# metric_for_best_model="overall_f1",
# push to hub parameters
report_to="tensorboard",
push_to_hub=False,
hub_strategy="every_save",
hub_model_id=repository_id,
hub_token=HfFolder.get_token(),
)
# Create Trainer instance
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"],
compute_metrics=compute_metrics,
)我们可以开始用Trainer的train方法开始我们的训练了。
# Start training
trainer.train()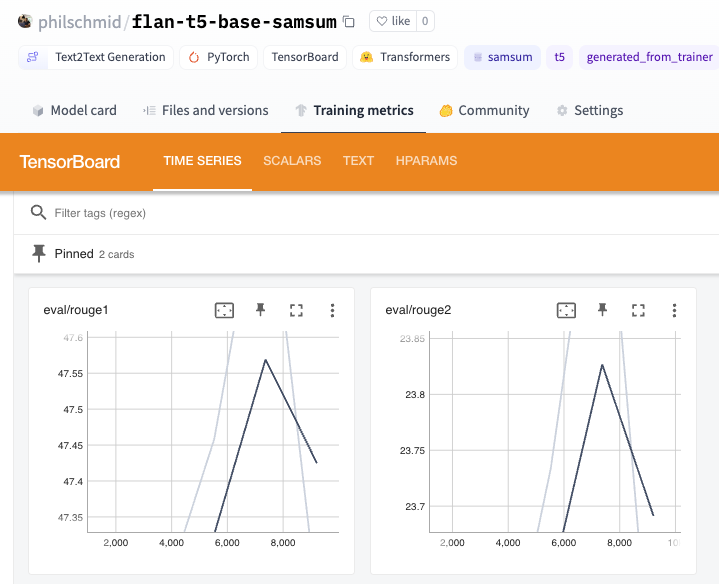
很好,我们已经训练好了模型。让我们在测试集上再次评估最佳模型。
trainer.evaluate(){'eval_loss': 1.3715944290161133,
'eval_rouge1': 47.2358,
'eval_rouge2': 23.5135,
'eval_rougeL': 39.6266,
'eval_rougeLsum': 43.3458,
'eval_gen_len': 17.39072039072039,
'eval_runtime': 108.99,
'eval_samples_per_second': 7.514,
'eval_steps_per_second': 0.945,
'epoch': 5.0}我们取得的最好成绩是rouge1 ,得分 47.23。
让我们将结果和标记符保存到 "Hugging Face Hub",然后创建一张模型卡。
# Save our tokenizer and create model card
tokenizer.save_pretrained(repository_id)
trainer.create_model_card()
# Push the results to the hub
trainer.push_to_hub()4.运行推理
现在我们有了一个训练有素的模型,可以用它来运行推理。我们将使用转换器中的 pipeline API 和数据集中的测试示例。
from transformers import pipeline
from random import randrange
# load model and tokenizer from huggingface hub with pipeline
summarizer = pipeline("summarization", model="philschmid/flan-t5-base-samsum", device=0)
# select a random test sample
sample = dataset['test'][randrange(len(dataset["test"]))]
print(f"dialogue: \n{sample['dialogue']}\n---------------")
# summarize dialogue
res = summarizer(sample["dialogue"])
print(f"flan-t5-base summary:\n{res[0]['summary_text']}")dialogue:
Abby: Have you talked to Miro?
Dylan: No, not really, I've never had an opportunity
Brandon: me neither, but he seems a nice guy
Brenda: you met him yesterday at the party?
Abby: yes, he's so interesting
Abby: told me the story of his father coming from Albania to the US in the early 1990s
Dylan: really, I had no idea he is Albanian
Abby: he is, he speaks only Albanian with his parents
Dylan: fascinating, where does he come from in Albania?
Abby: from the seacoast
Abby: Duress I believe, he told me they are not from Tirana
Dylan: what else did he tell you?
Abby: That they left kind of illegally
Abby: it was a big mess and extreme poverty everywhere
Abby: then suddenly the border was open and they just left
Abby: people were boarding available ships, whatever, just to get out of there
Abby: he showed me some pictures, like <file_photo>
Dylan: insane
Abby: yes, and his father was among the people
Dylan: scary but interesting
Abby: very!
---------------
flan-t5-base summary:
Abby met Miro yesterday at the party. Miro's father came from Albania to the US in the early 1990s. He speaks Albanian with his parents. The border was open and people were boarding ships to get out of there.








